
上海园区招商办公室
联系人:梁经理
联系电话:15000456391
欢迎来电咨询,竭诚为你服务!
本文共计2584字,预计阅读时长二十分钟
神经网络与深度学习
前言
1.神经元的构成:
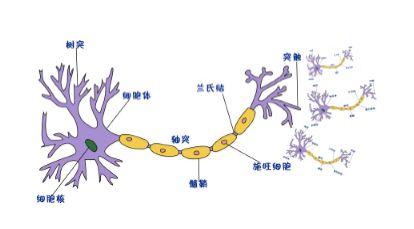

2.树突:神经元接收信号的部位,多个
3.轴突:神经元输出信号的部位,一个,但是在末端可以分叉,即神经末梢
4.突触:神经末梢与其他神经元的树突接触的区域(当然也可以与胞体直接接触)
5.神经网络:是指一种结构,指类似于神经元之间形成的一种网络状的结构。下图即为人工神经网络(Artificial Neural Networks,简写为ANNs)
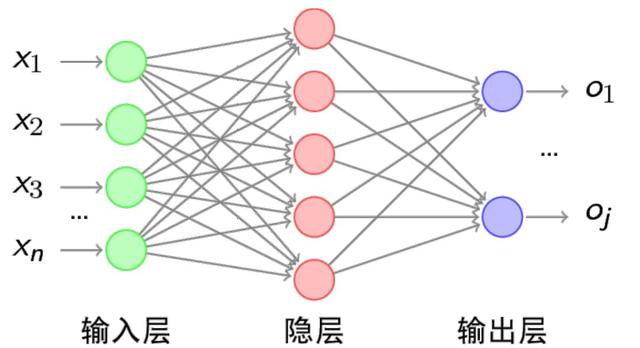
6.人工智能、机器学习、神经网络、深度学习之间的关系

– 神经网络和深度学习都属于机器学习的一种
– 深度学习是神经网络的一大分支
– 深度学习的基本结构是深度神经网络
7.深度学习能否取代传统机器学习?
? 有的观点认为:深度学习会导致其他机器学习算法濒临灭绝,因为其有着非常卓越的预测能力,尤其大规模数据集上。
? 有的观点认为:传统机器学习算法不会被取代,深度学习容易把简单问题复杂化,深度学习适合不可知域,若有领域知识的话,传统算法表现更好。
下面进入正文内容 》》》》》》》
一、什么是神经网络
1.最简单的神经网络——线性感知机
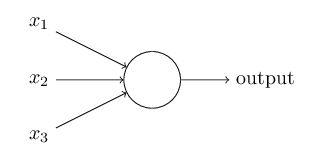
线性感知机的原理是根据输入的一维或多维信号p,预设w和b,经过处理后(S = p1*w1+p2*w2+…+pn*wn+1*b)得到一个输出值,再由输出值与实际值计算得到误差,对w和b进行更新,直到所有的样本都能被输出正确。但是感知机仅在线性可分的情况下有效,无法处理非线性问题。
2.遇到了非线性问题
对于非线性问题,之前SVM算法里解决办法是引入了一个新的概念:核函数。它可以将样本从原始空间映射到一个更高维的特质空间中,使得样本在这个新的高维空间中可以被线性划分为两类,即在空间内线性划分。(文末有SVM的传送门)
而另一种解决方法便是采用多个感知机,构成神经网络(所以传统神经网络也被称为多层感知机)。
3.神经网络基于感知机的扩展
1)加入了隐藏层,隐藏层可以有多层,增强了模型的表达能力,如下图实例
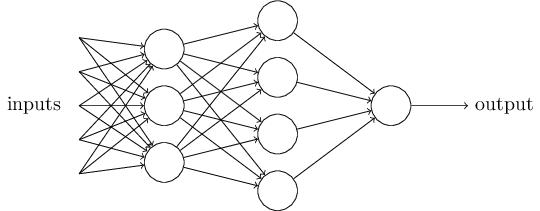
2)输出层的神经元也可以不止一个输出,可以有多个输出,这样模型可以灵活的应用于分类回归,以及其他的机器学习领域比如降维和聚类等。多个神经元输出的输出层对应的一个实例如下图,输出层现在有4个神经元了。
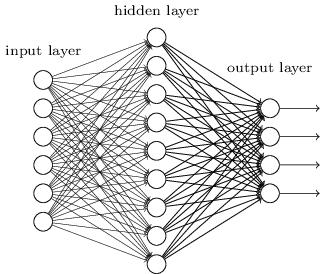
3)对激活函数做扩展,感知机的激活函数是sign(z),虽然简单但是处理能力有限,因此神经网络中一般使用的其他的激活函数,比如我们在逻辑回归里面使用过的Sigmoid函数。
二、如何训练神经网络
1.寻找特征
人类学习新事物的过程,是对一个物体总结出几个特征,再与以往的认知进行匹配,进一步进行识别或判断。人工神经网络也是类似,一般是综合一些细粒度的基础特征,最终得到几个可用的结构性特征。例如,一个个的像素点对于模型训练来说,意义不大,只有将粒度放大到一定程度,比如轮胎、车把等特征,才有利于模型的训练。
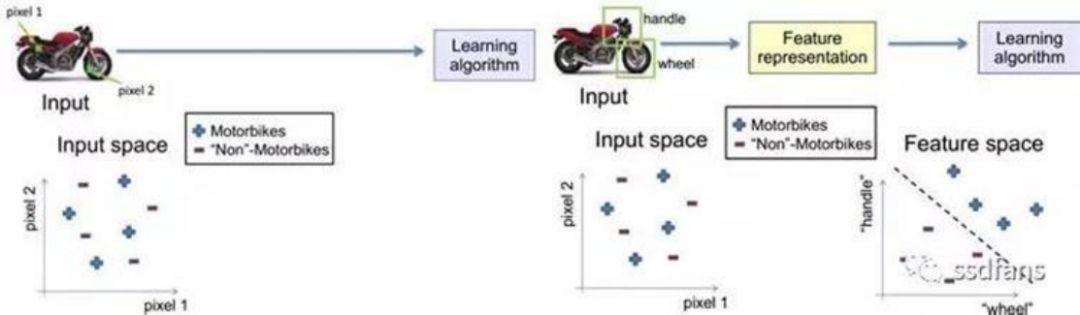
2.确定神经网络的结构
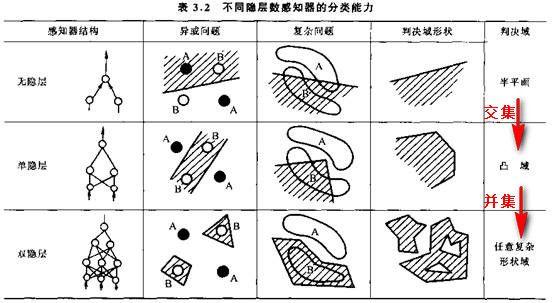
上图是不同结构的神经网络(多层感知机)可以解决的问题,一般来说,双隐层神经网络能够解决任意复杂的分类问题。
3.确定(隐层)的节点数量
以一个三层的神经网络为例,一般有几个经验:
1)隐层节点数量一定要小于N-1(N为样本数)
2)训练样本数应当是连接权(输入到第一隐层的权值数目+第一隐层到第二隐层的权值数目+…第N隐层到输出层的权值数目,不就是边的数量么)的2-10倍(也有讲5-10倍的),另外,最好将样本进行分组,对模型训练多次,也比一次性全部送入训练强很多。
3)节点数量尽可能少,简单的网络泛化能力往往更强
4)确定隐层节点的下限和上限,依次遍历,找到收敛速度较快,且性能较高的节点数
4.训练神经网络
? BP算法
Back Propagation,也称为Error Back Propagation(误差反向传播法),实现步骤见下图(多看几遍就清晰了):
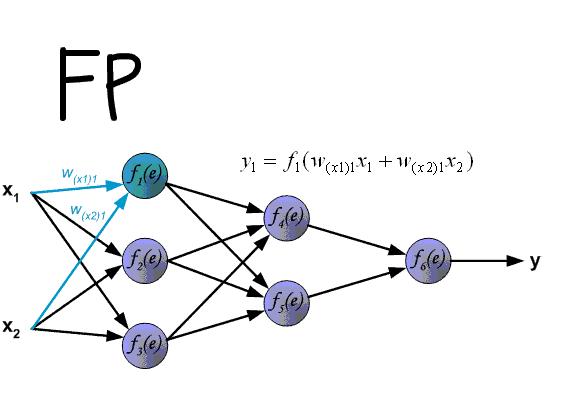
– 信号正向传播(FP):样本由输入层传入,经过各个隐层逐层处理后,传向输出层,若输出层的实际输出和期望的输出不符,则转入误差的反向传播阶段。
– 误差反向传播(BP):将输出以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号,此误差型号即为修正各个单元权值的依据。
BP算法的缺点:
1)5层以内的神经网络,可以选择用BP算法训练,否则效果不理想,因为深层结构涉及多个非线性处理单元层,属于非凸目标函数,普遍存在局部最小,使得训练困难
2)梯度越来越稀疏:从顶向下,误差矫正信号越来越小
3)只能用带标签的数据进行训练,而大部分数据是没有标签的,但是我们大脑是可以从没有标签的数据中学习
三、引入深度学习
2006年,深度神经网络(DNN)和深度学习(deep learning)概念被提出来,神经网络又开始焕发一轮新的生命。事实上,Hinton研究组提出的这个深度网络从结构上讲,与传统的多层感知机没有什么不同,并且在做有监督学习时算法也是一样的。唯一的不同是这个网络在做有监督学习前要先做非监督学习,然后将非监督学习学到的权值当作有监督学习的初值进行训练。
1.为了解决非监督学习的过程→自动编码器
①自动编码器(Auto Encoder)
? 无标签,用非监督学习方法学习特征
? 给定一个神经网络,假定输入输出是相同的,然后训练调整其参数,得到每一层的权重
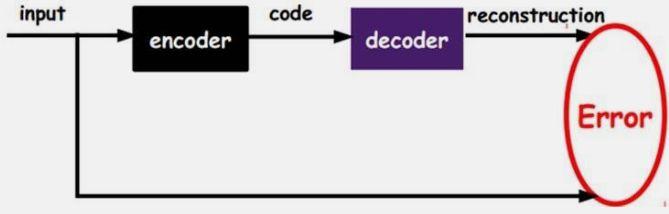
? 通过编码器产生特征,然后训练下一层,逐层下去
? 一旦监督训练完成,该网络就可用来做分类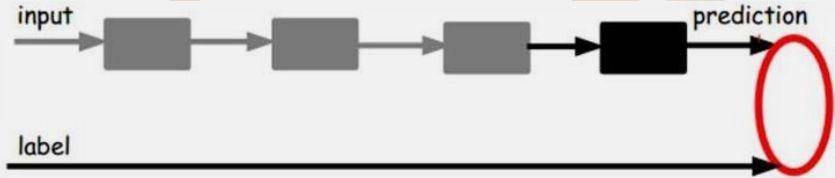
? 神经网络顶层可以作为一个线性分类器,我们 可以用一个更好性能的分类器替代它
②稀疏自动编码器(Sparse Auto Encoder)
? 目的:限制每次得到的表code尽量稀疏,因为稀疏的表达往往比其他表达要有效
? 做法:在AutoEncoder基础上加了L1正则
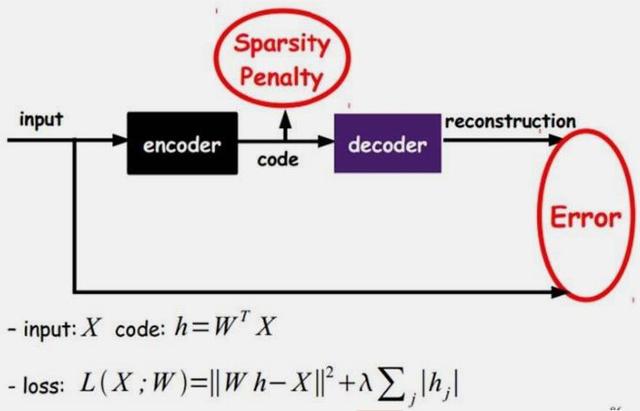
③降噪自动编码器(Denoising Auto Encoder)
? 训练数据中加入噪声,所以自动编码器会自动学习如何去除噪声,从而获得没有被噪声污染过的输入,泛化能力更好
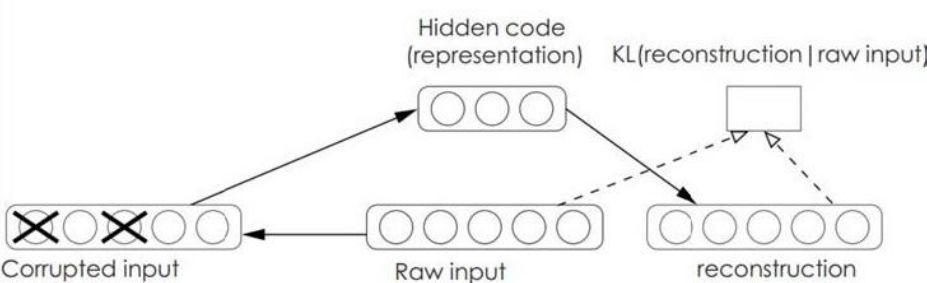
2.为了解决DNN的全连接→卷积神经网络CNN
①卷积层(Convolution)
当DNN在处理图片的时候,如果继续沿用全连接的话,数据量会异常的大。例如
对于一个1000 * 1000像素点的图像,用1000 * 1000个神经元去记录数据,采用全连接的话,1000 * 1000 * 1000 * 1000 = 10^12个连接,即要训练10^12个参数
如果采用局部感受野,令一个神经元记录10*10的区域,训练的参数可以降到10^8个。
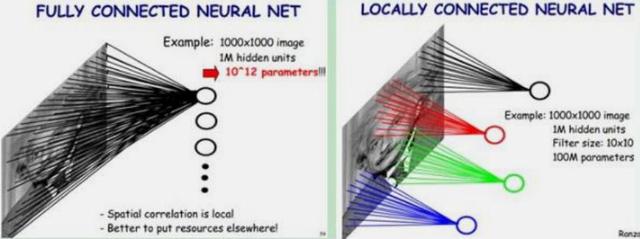
进一步采用权值共享,让所有神经元共享一套权重值(滤波器Filters),用这个滤波器在原图上滑动扫描后便会得到一个feature map(图像的一种特征),根据自编码模型,只有一个特征对模型来说,过于简单了,学不出什么规律,因此换用不同的滤波器,便可以得到不同的 feature map(特征),如选用100个滤波器,得到100个feature map,每个map是10*10,最终的参数为100*10*10 = 10^4。
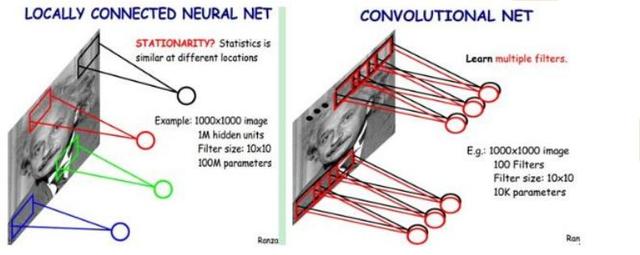
由滤波器得到feature map的动态图如下:
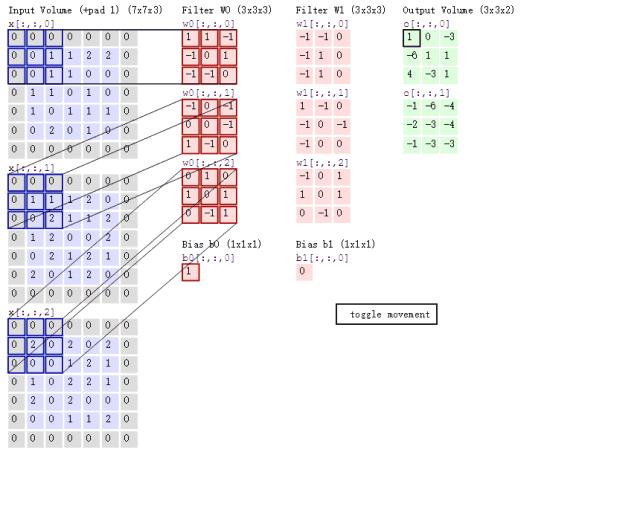
因为在用滤波器一个步长一个步长往后面扫描的时候,涉及到了一个时序的问题,即卷积的过程
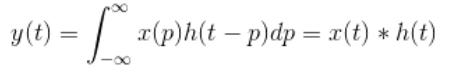
因此滤波器在扫描的之前,要先翻转180°,这个时候我们称这个滤波器为卷积核。翻转180°的具体论证过程见链接:
https://blog.csdn.net/zy3381/article/details/44409535
②池化层(Pooling)
作用是在不变性的情况下减少参数,例如平移、旋转、缩放等
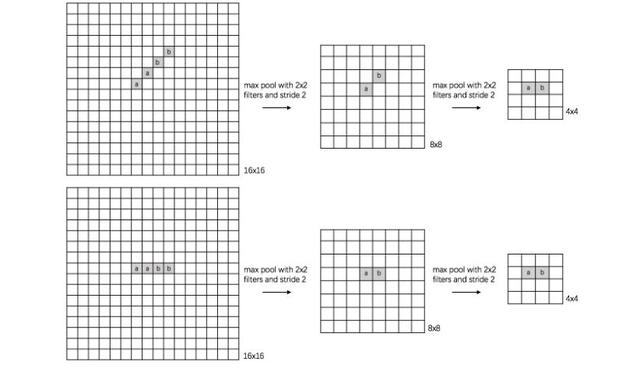
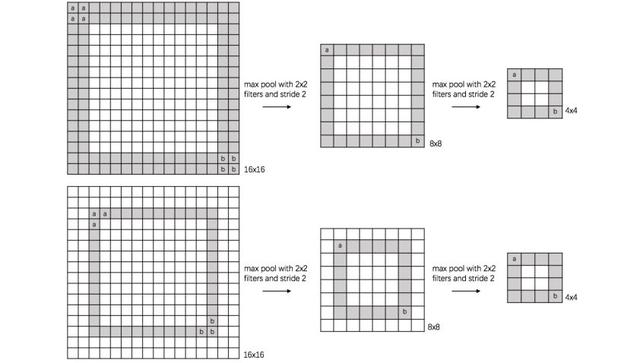
③典型结构
CNN一般采用卷积层和池化层交替设置,即一层卷积接一层池化层,池化层后接一层卷积层,最后几层可以采用全连接或高斯连接
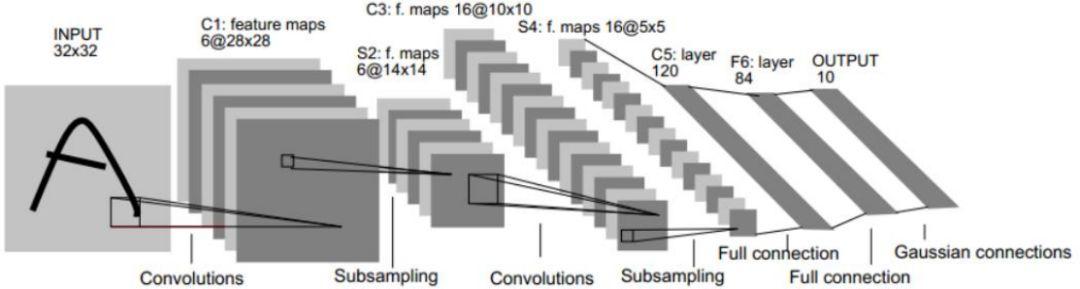
④训练过程
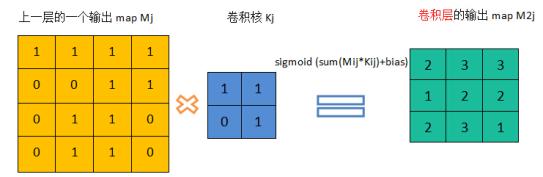
卷积层:
– Map个数取决于卷积核个数,常用的6或者12
– 第j个map的输出计算:上一层所有map跟自己对应的卷积核做卷积然后求和,再加上偏置,求sigmoid函数
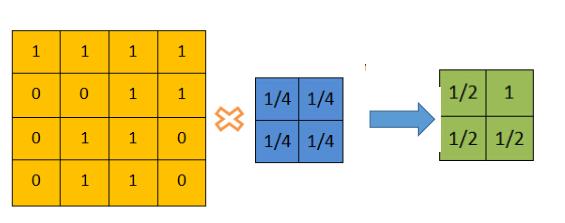
采样层:
– 对上一层map的相邻小区域进行聚合统计(最值或者均值)
(任何疑问建议,欢迎留言评论~)

如若转载,请注明出处:https://www.dhuoke.com/8419.html
相关推荐
-
星月金融湾租赁中心
1. 星月金融湾租赁中心——助力企业创新发展 随着中国金融市场的不断开放和创新,上海作为全国金融中心城市,吸引了大量金融机构和创新企业的关注。为了满足企业对于一流办公环境和专业服务…
-
恒生万鹂广场(办公)招商信息
1. 恒生万鹂广场(办公)招商起始 恒生万鹂广场,坐落于上海市核心商务区黄浦区,是一座集商业、写字楼、会所于一体的城市综合体。广场以现代化设计理念为基础,拥有出色的建筑结构和高品质…
-
松港1088创意园诚邀您的入驻
1. 松港1088创意园:打造创业者的乐园 松港1088创意园位于上海市浦东新区,是一个专为创业者提供创新创业环境的综合性商业园区。园区占地约100亩,提供办公、研发、展示和社交交…
-
京东金条欠三年才联系朋友(京东金条欠一年)
这这几天已经有好多网贷开始逾期了 。总共欠了有十几个网贷,一共欠款达到要67万左右,网贷利率也从刚开始的15%左右,慢慢开始借到有24%的,也有36%的。都是不断拆东墙补西墙,借新…
-
同华大厦(商住楼)火热招租
1. 火爆招商,同华大厦期待与您携手共进! 同华大厦,位于上海市黄浦区的繁华商业中心地带,拥有得天独厚的地理位置和便捷的交通网络,因而备受市场关注。作为一座集商务办公、商业零售和住…
-
周浦先进制造产业园区火热招租
1. 周浦先进制造产业园区简介 周浦先进制造产业园区位于上海市,占地面积约500亩,拥有现代化厂房和配套设施。园区专注于引进先进制造业企业,致力于打造一个创新、高效、环保的产业集聚…
-
雅马哈r6二手车交易市场(雅马哈r6二手车市场)
最近几年国内摩托车文化与市场日益蓬勃,现如今摩托车不仅仅是具备出行代步的功能,也成为了许多爱好者交友的工具,让骑行变成生活当中重要的组成部分。但对于很多打算进入摩托车圈子的新手来说…
-
张江创新园租赁中心
1. 张江创新园租赁中心:开启创新之门 张江创新园租赁中心位于上海张江高科技园区,坐落于中国科技创新的核心区域。该中心是为满足企业创新发展需求而专门打造的一站式服务平台。无论是初创…
-
影响力pdf(影响力PDF下载)
《影响力》作者是罗伯特 西奥迪尼,著名的心理学家。本书是《财富》杂志鼎力推荐的75本商业图书之一,翻译成多个国家的语言经久流传。 本书主要从心理学让我们明白我们是如何被别人影响的,…
-
上海富力环球中心-招商中心
位于闵行区西南部,黄浦江上游北畔的马桥镇,是一个历史悠久的地方,拥有4000年的马桥文化,被誉为“上海之本”。为了实现现代化强镇的目标,马桥镇致力于全面建设人文、生态、智慧的发展。…